Exception Handling
Either you handle your exceptions or they will handle you
This is designed to support decision-making related to what to do when an exception is being thrown. Should you even catch it? If you do, do you just log it or do you rethrow it? Should you encapsulate it into another one? For that purpose, we need to review some key concepts around how exceptions are structured and what treating means.
TL;DR
I started this post by explaining how exceptions work in Java. If you already know it, just skip to “When to do what?”.
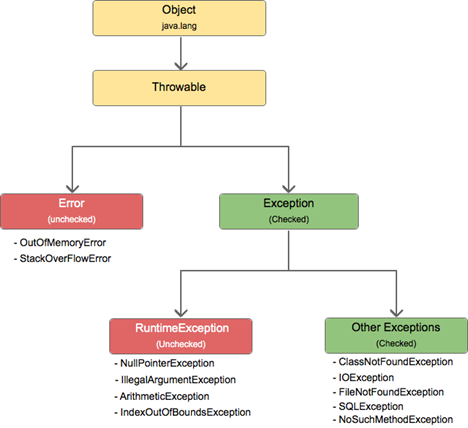
Java Exceptions — mind the hierarchies!
To introduce this topic, it is important to explain how the exception mechanism works in Java.
Anything that inherits from Throwable can be thrown and it works exactly as any exception does.
And how does it work?
public static void main(String[] args) {
try {
int[] myNumbers = {1, 2, 3};
String text = null;
if (myNumbers[2] == 50) { //This will never be true
text = "OK"; //text will not be initialized.
}
System.out.println(text.length()); //This will throw a NullPointerException.
System.out.println("The end."); //This will never be executed.
} catch (NullPointerException exception) {
System.out.println("Something went wrong:" + e.getMessage());
throw exception;
} finally {
System.out.println("The 'try catch' is finished."); //This will always be printed.
//if this next line wasn't commented, the NullPointerException
// thrown on line 8 would be lost.
//throw new Exception("erasure");
}
//Here goes code that will work correctly
// AND MAKES SENSE even if the code in the try block doesn't work.
}Basically, when an exception is thrown, the execution of the code stops. No line after the exception is thrown executes, unless the exception is handled by a catch block.
An exception is handled in the first catch block that declares a matching type (i.e., if there is a catch with that class or any superclass in its hierarchy), the catch block is executed.
Only one catch block is executed and it is the first that declares a matching type.
finally blocks are always executed, even if there is no catch block that matches the exception (or no catch block at all). When an exception is being thrown (either because of the lack of a matching catch block or because the catch block rethrows it - or throws a new one), the finally block is executed before the exception is thrown to the caller method. Therefore, we have to be extra careful with the code inside the finally block. If anything is thrown there (another exception, for instance), the original exception will not be thrown. It will be replaced by the one that originated in the finally block.
If you like this post, please share it (you can use the buttons in the end of this post). It will help me a lot and keep me motivated to write more. Also, subscribe to get notified of new posts when they come out.
Checked vs Unchecked
Checked exceptions are the ones that the Java language obligates the developer to either catch or explicitly declare that the method throws it. They are “checked” at compile-time, thus the name. All the checked exceptions inherit directly from Exception or any other subclass that does not have RuntimeException in its hierarchy.
Runtime exceptions represent problems that are the result of a programming problem, and as such, the API client code cannot reasonably be expected to recover from them or to handle them in any way. Such problems include arithmetic exceptions, such as dividing by zero; pointer exceptions, such as trying to access an object through a null reference; and indexing exceptions, such as attempting to access an array element through an index that is too large or too small.
Runtime exceptions can occur anywhere in a program, and in a typical one, they can be very numerous. Having to add runtime exceptions in every method declaration would reduce a program’s clarity. Thus, the compiler does not require that you catch or specify runtime exceptions (although you can). And just because the method cannot recover from it, it doesn’t mean that your application can’t. You can sometimes execute it differently, simply retry, attempt to correct the problem before trying again, or even execute a different business rule.
Context and abstraction levels
What does this method do?
public static String fileToString(String filePath) throws IOException {
File file = new File(filePath);
StringBuilder content = new StringBuilder();
try (BufferedReader bufferedFileReader = new BufferedReader(new FileReader(file))){
while (bufferedFileReader.ready()) {
content.append(bufferedFileReader.readLine());
content.append(System.getProperty("line.separator"));
}
if (content.length() != 0) {
content
.deleteCharAt(content.lastIndexOf(System.getProperty("line.separator")));
}
}
return content.toString();
}It ONLY reads data from a file. Nothing else. How could we possibly predict, by looking to this method, that it reads the contents of a configuration file?
public Configuration loadConfiguration(Organization organization)
throws DataNotAvailableException {
log.trace("Loading configuration %.", organization.getId());
Configuration configuration = new Configuration();
try{
configuration.parse(FileLoader.fileToString(organization.getConfigurationFilePath()));
log.debug("Configuration loaded %.", organization.getId());
} catch (FileNotFoundException exception) {
log.warn("No configuration found for organization %, loading default configuration.",
organization.getId(), exception);
configuration.loadDefaults();
} catch \(IOException | ParseException exception) {
log.error("Configuration file possibly corrupted, organization %.",
organization.getId());
throw new DataNotAvailableException("Error loading or parsing configuration data" +
" for organization %.", organization.getId(), exception);
}
return configuration;
}This method could be loading configuration for a desktop application, right? Or it could be called inside a REST microservice. How could we tell that this is a web application?
@WebServlet("/login")
public class LoginServlet extends HttpServlet {
@EJB
private OrganizationService organizationService;
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String organizationId = request.getParameter("organizationId");
try {
//this is where the configuration gets loaded.
Organization organization = organizationService.find(organizationId);
request.getSession().setAttribute("user", user);
response.sendRedirect("home");
} catch (OrganizationNotFoundException exception) {
log.error(exception);
request.setAttribute("error", MessageBundle.find("error.organizationNotFound"));
request.getRequestDispatcher("/login.jsp").forward(request, response);
} catch (DataNotAvailableException exception) {
log.error(exception);
request.setAttribute("error",
MessageBundle.find("error.organizationDataNotLoaded"));
request.getRequestDispatcher("/login.jsp").forward(request, response);
} catch (Throwable throwable) {
log.error(t);
request.setAttribute("error", MessageBundle.find("error.internalError"));
request.getRequestDispatcher("/login.jsp").forward(request, response);
}
}
}The importance of understanding what your method is designed to do and in which context it is will be the most relevant piece of information in order to determine what you can and should do with the exception.
Note
In a real-life situation, you should have an exception handling framework built into your application. That means that your application-specific exceptions inherit from a common root, that you have a standard of how to log them and how to access what was logged, maybe ways to get automatically notified when something serious happens but also that all your top-level classes deal with throwable. In the example above, it means that your LoginServlet would probably share a common root with all your other servlets:
public abstract class ApplicationServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
try {
executePost(HttpServletRequest request, HttpServletResponse response);
} catch (Throwable throwable) {
log.error(t);
request.setAttribute("error", MessageBundle.find("error.internalError"));
request.getRequestDispatcher("/login.jsp").forward(request, response);
}
}
//LoginServlet should override this method, there will be no need to duplicate
// catch (Throwable throwable) in any servlet.
protected abstract void executePost(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException;
}
@WebServlet("/login")
public class LoginServlet extends ApplicationServlet {
@EJB
private OrganizationService organizationService;
@Override //overrides the executePost method from ApplicationServlet
protected void executePost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String organizationId = request.getParameter("organizationId");
try {
//this is where the configuration gets loaded.
Organization organization = organizationService.find(organizationId);
request.getSession().setAttribute("user", user);
response.sendRedirect("home");
} catch (OrganizationNotFoundException exception) {
log.error(exception);
request.setAttribute("error", MessageBundle.find("error.organizationNotFound"));
request.getRequestDispatcher("/login.jsp").forward(request, response);
} catch (DataNotAvailableException exception) {
log.error(exception);
request.setAttribute("error",
MessageBundle.find("error.organizationDataNotLoaded"));
request.getRequestDispatcher("/login.jsp").forward(request, response);
}
}
}When to do what?
Let it through
The fileToString method cannot infer anything about its use or intent. Therefore, if it was to catch the exception, there is no way to determine what to do with it. The options would be to bury it (empty catch block) or let it through. Burying an exception is unacceptable. It leads the caller method to “believe that everything went well” and proceed with the execution of the code under an error state. This prevents an appropriate treatment to happen at higher layers and could cause data corruption/loss.
Therefore, the ultimate decision to catch it or not is tied to answering the question:
Is there anything I can do to treat this or help the caller method to treat it?
NO: Let it through. Declare that the method throws this exception and be happy.
YES: Catch it. And be happy too.
Catch
Complete treatment
A complete treatment is when your code can resume the processing and the original request from the external agent (user, another system, etc.) can be fulfilled.
That means that you have either:
-
Fixed the conditions that caused the exception and tried again.
Extremely valuable when you can recognize what went wrong. -
Retried a number of times and one of them worked.
Very common in network issues, like timeouts. -
Took an alternative course of action.
The methodloadConfigurationdoes exactly that in theFileNotFoundExceptioncatch block.
In other words, the processing is recoverable and all the necessary steps to recover were completed successfully.
Note
Only when you complete the treatment and recover fully you are allowed to “consume” the exception. If that is not the case, you either rethrow it or encapsulate (wrap it) in a new one that must be thrown.
Partial treatment
A partial treatment is when something can be done to ease the impact of the code not being completely executed or when extra information can be added. Examples of extra information could be:
-
to assist the caller method in treating and possibly recovering from the issue.
-
to eliminate or roll back side-effects of partially executed code.
-
to inform another agent (log the event, send a notification, etc.), often to assist in troubleshooting. A catastrophic failure could also notify support teams immediately.
-
to raise the abstraction level by encapsulating the exception in another one.
The loadConfiguration method has a catch block for IOException and ParseException that does 3 of these. In particular, it logs information, raises the abstraction level by encapsulating the exception in a new one, and adds valuable information in the new one to assist with troubleshooting.
Encapsulate it or not?
The question about encapsulation (or wrapping) is really tied to the abstraction level of the layer where the code is being executed. Note that JPA has a QueryTimeoutException that is a superclass of PersistenceException to encapsulate a timeout exception that might occur if there are network issues in the communication with the database. That happens because JPA is a higher-level abstraction over JDBC and SQL. JDBC, on the other hand, encapsulates a Timeout with a SQLTimeoutException.
In the same spirit, the loadConfiguration method encapsulates the IOException and the ParseException in a DataNotAvailableException. Thanks to that, if in the future this information is stored in the database and no parsing is needed, there would be no need to change the caller method. All that the caller needs to know is that the data is not available. Knowing where it was stored doesn’t help to decide what to do. If there was something to do regarding that aspect, it should be the responsibility of the loadConfiguration method to treat that aspect, being this treatment a partial or a complete one.
In order to correctly encapsulate an exception, always set the cause when creating a new exception because one has already occurred. For that purpose, use the constructors that allow passing in a cause:
-
public Throwable::(String message, Throwable cause)(the most popular one); -
public Throwable::Throwable(Throwable cause)(avoid this one, always prefer to pass a message). public Throwable::(String message, Throwable cause, boolean enableSuppression, boolean writableStackTrace)
Or call the public Throwable Throwable::initCause(Throwable cause) method to set it after creating the exception. This method is not preferred as it is easy to forget to call it.
Example (from method loadConfiguration above):
} catch \(IOException | ParseException exception) {
log.error("Configuration file possibly corrupted, organization %.",
organization.getId());
throw new DataNotAvailableException("Error loading or parsing configuration data" +
" for organization %.", organization.getId(), exception);
// ^ Message ^ Cause
}Non-recoverable situations
In the case of non-recoverable situations, it is important to not let the code continue to execute. Executing in an error state may cause other errors and cause data loss/corruption.
Roll back any partial processing effects (if any) and inform the requester that the processing could not be executed. In the doPost method, it was done extensively by adding error messages to the user.
Usually, these external agents (user, another system, etc.) notifications can only be done in the methods that are closer to the beginning of the request (deeper in the stack).
In the case of this example, the first method that runs on the server side is responsible for this notification. It is common in asynchronous methods that a notification of the results (including possible error messages) is issued by email, push notifications (mobile devices), or even in system reports.
In the case of backend processing (like batch jobs that run under a schedule), database tables and data files are often used to store results and error messages.
Not notifying that something went wrong not only makes the caller assume that the request was successfully processed and the goal was achieved but also caps the technical analysis conducted by developers and often makes it hard to reproduce the issues. An issue that is not logged and doesn’t trigger any notification is referred to as a silent failure.
Silent failures may create other problems that could trigger other non-silent failures. Reproducing or investigating these subsequent non-silent errors may prove to be exceptionally harder because the root cause might have happened at a different time, in a different step of the business process.
Logging and exceptions
Logging often goes with exceptions. Of course, a developer can decide to log anything, even perfectly working code. However, when exceptions occur, it is usually a good practice to log their occurrence.
Log levels
If you were able to recover from the exceptional situation and the intent of the method will still be achieved, it is generally accepted that a log level of WARN or below should be used. Levels below WARN (usually INFO, as DEBUG and TRACE are associated with other purposes) are usually applicable for when there was no loss in the method’s result. E.g., in the loadConfiguration method, the catch FileNotFoundException could not load the organization configuration. It assumes it is a new organization. This assumption is not without a possible loss (i.e., if there was a file stored somewhere else or lost for some external reason). In this case, WARN would be appropriate. If otherwise, an attempt to fetch configuration from a secondary location was performed successfully, a level below WARN would be more appropriate.
If there was a catch-and-throw with a partial treatment, it is generally accepted that WARN is an appropriate level since there is no way to tell if the caller method will be able to recover or not, but it is important to remark that something went wrong and the method did not complete its execution appropriately.
However, if the catch block does not do partial treatments and only encapsulates it, there is no need to log anything as long as the encapsulation keeps the original exception intact so its stack trace can be accessed at another layer. If this is not the case, a log of level WARN is probably appropriate.
Logs at the ERROR level are reserved for situations when the method cannot recover and the processing of the request cannot continue. These are usually associated with situations where an external agent (the user, another system, etc.) needs to be informed that the original request was not completed.
Therefore, logging at the ERROR level usually indicates that the exception needs to be rethrown or encapsulated in another before being thrown and avoid the code to continue running under an error state that may cause data corruption/loss and other unexpected results — or even let the user believe that his request was completed successfully.
What to log
For a complete guide on logging practices, visit this other post: To log or not to log?

SEM Blog | To log or not to log?
The most important information is the throwable/exception message (public String Throwable::getMessage()), the class and method/source code line where it happened, and its type (the exception class name), of course.
However, this is often not enough to investigate the cause of the exception. For that purpose, make sure that the stack trace is also logged. This allows a developer to trace the method calls up to the point of failure.
Another very important piece of information that is often needed is the cause of the exception. Whenever an exception encapsulates another one, the encapsulated exception is treated as the “cause”.
The cause can be accessed by calling the Throwable method public Throwable Throwable::getCause(). Usually, when the stack trace is fully logged, the cause will be reported there (see line 8 below):
Exception in thread "main" java.lang.RuntimeException: Some other message
at Exceptions.main(Exceptions.java:4)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:147)
Caused by: java.lang.RuntimeException: Some message
at Exceptions.main(Exceptions.java:3)
... 5 moreSo, summarizing:
- the throwable/exception message (
public String Throwable::getMessage()); - class and method/source code line where it happened;
- Its type (the exception class name);
- the stacktrace including the cause (preferred) OR the stack trace and the cause separately.
Always make sure that your exception handling framework (and/or any 3rd party libraries you may be adopting) capture all this information. Preferably, simply passing an exception instance to the framework should be enough to capture all this information automatically.
It is important to note that if you will throw (or rethrow, or encapsulate) the exception in a catch block, it is ok to log extra information (like variables that may be available in the method scope only) that will help with a future investigation but avoid logging the stack trace. It will be available to the caller methods in the stack and if several of them do that, you will end up with several repeated stack traces (all but one will be incomplete) for one single error.
Throwable and security
As you may have noticed, when an exception is not treated appropriately, a stack trace may be dumped in system logs or at any other place depending on the application. This may pose a security issue, especially with web applications, as the stack trace may appear on a web page exposing the inner workings of the application to external agents.
This is why it is generally considered good practice to catch Throwable at the highest layer of the application, log what happened at the ERROR level and inform the external agent (user, another system, etc.) of the failure in abstract/generic terms.