Seven unspoken truths about Software Tests
Things that are usually not taught at universities or courses, but everyone should know
- When in charge of tests, were you ever questioned why you didn’t catch a specific defect? Have you ever blamed someone for not catching a defect?
- Have you increased your test coverage only to discover that the number of defects in production is about the same?
- Have you spent more time than ever testing before releasing only to find that you couldn’t catch anything else (and as soon as you released, the defects started to come in)?
- Can developers test their code?
- Will defects will have exponentially increased costs if caught later?
- Can you try to find defects by tweaking the software in any way you want and call it “exploratory testing”?
- Do you need to employ QA activities to improve the quality of the product?
Let’s see if we can bust some myths around software testing!
1. Tests won’t catch everything!
That is right. No QA activity will catch all existing defects.

| Techniques | Effectiveness |
|---|---|
| Software review | 25% to 40% |
| Software inspection | 45% to 65% |
| Code review | 20% to 35% |
| Code inspection | 45% to 70% |
| Unit test | 15% to 50% |
| Integration test | 25% to 40% |
| System test | 25% to 55% |
| Beta test (< 10 users) | 24% to 40% |
| Beta test (> 1000 users) | 65% to 85% |
Adapted from Caper Jones, Software defect-removal efficiency, IEEE Computer, April 1996, pp. 94 - 95, DOI 10.1109/2.488361, ISSN 1558-0814.
Some testing practices are actually less efficient than just inspecting the code. The point is not to choose what type of test you need to focus on but to combine some of them to yield better results with less effort.
So, next time anyone complains that a defect wasn’t caught, remind them that there is no way to ensure that a specific defect wasn’t caught.
Finding out why a defect was missed from a test is ex post facto analysis. It’s backward thinking. It’s the equivalent of saying that a magic trick is obvious after it was already disclosed how it was done. It’s not a valid analysis.
Never blame a QA Engineer. They are there to find the defects that were introduced. They are not causing them. The effectiveness of the tools to catch them is as flawed as the effectiveness of preventing the defects from being introduced in the first place. Nothing is perfect.
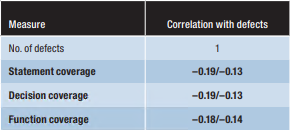
2. Test coverage has little (if any) correlation to the effectiveness of testing

Yes, you read that right. We already have enough scientific evidence to say that increasing unit test coverage may not necessarily increase your test suite effectiveness in finding defects! Maybe it’s time to focus on what is relevant to test rather than how much code is being tested.
The references below come from:
V. Antinyan and M. Staron, “Mythical Unit Test Coverage,” 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), 2019, pp. 267–268, DOI: 10.1109/ICSE-SEIP.2019.00038.
-
A. Mockus, N. Nagappan, and T.T. Dinh-Trong, “Test Coverage and Post-verification Defects: A Multiple Case Study,” Proc. 3rd Int’l Symp. Empirical Software Eng. and Measurement (ESEM 09), 2009, pp. 291–301.
The correlation between coverage and defects was none or very weak. Moreover, the effort required to increase the coverage from a certain level to 100% increased exponentially. -
M.R. Lyu, J. Horgan, and S. London, “A Coverage Analysis Tool for the Effectiveness of Software Testing,” IEEE Trans. Reliability, vol. 43, no. 4, 1994, pp. 527–535.
Qualitative analysis found no association between the defects and coverage. -
B. Smith and L.A. Williams, A Survey on Code Coverage as a Stopping Criterion for Unit Testing, tech. report TR-2008–22, Dept. of Computer Science, North Carolina State Univ., 2008, pp. 1–6.
The results did not support the hypothesis of a causal dependency between test coverage and the number of defects when testing intensity was controlled for. -
L. Briand and D. Pfahl, “Using Simulation for Assessing the Real Impact of Test Coverage on Defect Coverage,” Proc. 10th Int’l Symp. Software Reliability Eng., 1999, pp. 148–157.
The results did not support the hypothesis of a causal dependency between test coverage and the number of defects when testing intensity was controlled for. -
P.S. Kochhar, F. Thung, and D. Lo, “Code Coverage and Test Suite Effectiveness: Empirical Study with Real Bugs in Large Systems,” Proc. IEEE 22nd Int’l Conf. Software Analysis, Evolution, and Reengineering (SANER 15), 2015, pp. 560–564.
A moderate to strong correlation was found between coverage and defects. However, the coverage was manipulated and calculated manually. -
L. Inozemtseva and R. Holmes, “Coverage Is Not Strongly Correlated with Test Suite Effectiveness,” Proc. 36th Int’l Conf. Software Eng. (ICSE 14), 2014, pp. 435–445.
A weak to moderate correlation was found between coverage and defects. The type of coverage did not have an impact on the results. -
X. Cai and M.R. Lyu, “The Effect of Code Coverage on Fault Detection under Different Testing Profiles,” ACM SIGSOFT Software Eng. Notes, vol. 30, no. 4, 2005, pp. 1–7.
A moderate correlation was found between coverage and defects, but the defects were artificially introduced. The correlation was different for different testing profiles. -
G. Gay et al., “The Risks of Coverage-Directed Test Case Generation,” IEEE Trans. Software Eng., vol. 41, no. 8, 2015, pp. 803–819.
Coverage measures were weak indicators for test suite adequacy. High coverage did not necessarily mean effective testing.
3. Testing effort increases exponentially
Many sources state that a tester will find more defects at the beginning of the test activities and fewer at the end. There are indications that the effort to increase coverage and to execute the tests increase exponentially to find the next defect.
In the paper “Test Coverage and Post-verification Defects: A Multiple Case Study,” (A. Mockus, N. Nagappan, and T.T. Dinh-Trong, Proc. 3rd Int’l Symp. Empirical Software Eng. and Measurement (ESEM 09), 2009, pp. 291–301.), the effort required to increase the coverage from a certain level to 100% increased exponentially.
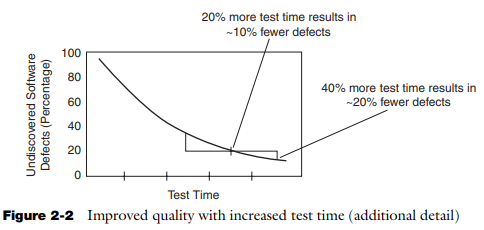
According to the authors in the book “Implementing automated software testing: How to save time and lower costs while raising quality.” (Dustin, E., Garrett, T., & Gauf, B. (2009). Pearson Education.), software reliability models show that the number of defects found per unit of time decrease exponentially as more time is invested in testing.
Book Title
by Authors
Identifier
4. Developer bias

Let’s say a developer understood a requirement wrong. The code will be implemented according to his misunderstanding — and so will the test.
If a developer forgets to do something in the code, like verifying a particular condition, the chances are that he won’t remember to test it either.
It’s as simple as that.
To avoid this issue, developers can test each other’s code, but not their own.
They could test their own code if they did not design the test cases, avoiding the aforementioned biases.
While Test Driven Development may reduce the bias of forgetting about something, it won’t reduce the bias of misunderstanding something.
5. Defects caught later may not cost much more to be fixed
I don’t even know how to start on this one because while it is true, it’s not what people usually say about it. Many of us are used to seeing pictures like these:
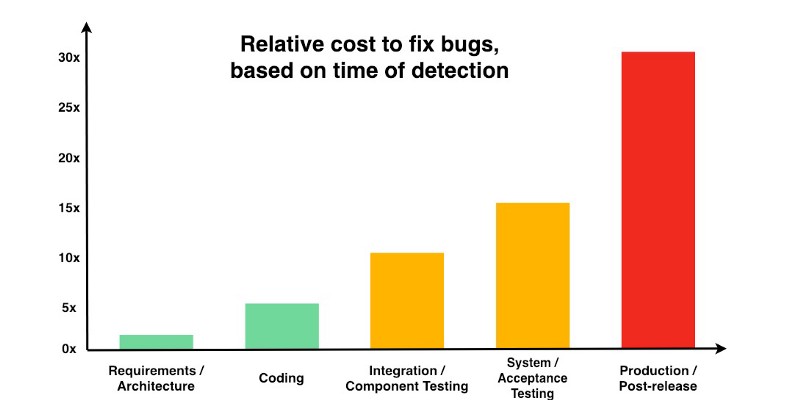
The only difference is the actual numbers, which sometimes top at 30x, 100x, or even 150x. Laurent Bossavit, an Agile methodology expert and technical advisor at software consultancy CodeWorks in Paris, has a post on GitHub called “Degrees of intellectual dishonesty” about how this information was apparently created out of thin air.
In the paper “Are delayed issues harder to resolve? Revisiting cost-to-fix of defects throughout the lifecycle” (Menzies, T., Nichols, W., Shull, F. et al. Empir Software Eng 22, 1903–1935 (2017) https://doi.org/10.1007/s10664-016-9469-x), authors have found NO evidence that the effort to fix a defect in the code takes longer after it goes into production.
In the paper “What We Have Learned About Fighting Defects” (Forrest Shull, Vic Basili, Barry Boehm, et al., Proceedings of the 8th International Symposium on Software Metrics (METRICS ‘02). IEEE Computer Society, USA, 249. 2002.) the authors identified that the cost of fixing certain non-critical classes of defects was almost constant across lifecycle phases (1.2 hours on average early in the project, versus 1.5 hours late in the project).
However,
Many of these studies measure the effort spent localizing the fault and fixing the defect in the code.
What do they miss?
- Regression tests!
Before we go into production, we execute a lot of regression tests. Often, manual testing is involved. Delivering certain defect fixes, especially critical ones, may require many tests to be re-executed. - Cost of opportunity!
At the time these defects are identified and fixed, many people will have moved on to the next tasks or even other projects. These tasks and projects will suffer from interruptions that may even put their deadlines in jeopardy. - Cost to the business!
That’s right! The business may have to pay penalties. The clients may be financially impacted. There will be an impact on the user experience.
In December 2020, the game Cyberpunk 2077 was removed from Sony’s store due to the many technical issues at launch. Sony offered full refunds. Later, the developer company CD Projekt Red announced refunds for PS4 and Xbox players. During an investor call, CD Projekt Red stated that “the cost of Cyberpunk 2077 fixes is “irrelevant” compared to restoring company reputation.” The company’s stock has gone from $31 a share in December 2020 to $10 a share in June 2021. - Defects that were not introduced in the code.
If a defect is injected into the code, it only needs to be fixed there. However, imagine if a defect was injected in a technical specification. The ramifications could impact multiple classes in different services or components. Imagine, for instance, the cost of deciding on an authentication framework that is not supported by a third-party service that won’t be able to validate an authentication token. If the defect is in a requirement, the cascading effect can be even worse.
All that without mentioning that if a fault is found in the code, it is expected that at least an investigation will happen to see if it was the technical specification that was wrong in the first place. And if the defect is there, the investigation continues to see if it came from the requirements.
So, while the effort of fixing a code fault may not increase that much after releasing, fixing defects earlier can save a lot of effort, money, and headaches.
6. Exploratory testing requires process and documentation
Many people think that if they go around trying to input unexpected data or execute actions out of sequence, at random, they are doing “exploratory testing”. They are not.
Exploratory testing doesn’t mean doing things ad hoc. Exploratory testing simply means that learning how the system works happens in parallel to defining and executing test cases.
In other words, exploratory testing can (and preferably should) be supported by existing documentation, such as requirements and manuals. The difference here is that the tests are not pre-scripted.
Testing scripts should be defined as part of the activity so that once a defect is spotted, the way to replicate it is documented. These scripts can later be automated or used in future manual tests (that won’t be exploratory anymore).
Test cases still should be defined using techniques such as Boundary-Value Analysis, Equivalence Class Partitioning, etc. There’s no reason to define random test cases that may not be cost-efficient or effective in detecting defects.
7. Improving non-QA activities in your process can improve your product’s quality
A 2009 study in Brazil (in Portuguese) involving 135 software development organizations had their capacity to identify and fix defects increased by improving their processes. These companies were part of a Brazilian software process improvement program called “MPS.Br,” where they should adhere to a software process improvement model (the MPS Model).
This model has stages, and 58 of these companies were in the first stage, where they were required to improve their Project Management and Requirements Management processes.
While it’s unclear why this happened, we can reasonably expect that projects that identify the right people to participate in the team, training needs, and proper budget and schedule will likely have the people, the time, and other resources to improve quality.
Bonus (fun fact): Bermuda Plan

OK, this is a funny one, but there is no explanation, and it may not really work.
Bermuda Plan is the name of a strategy to finish projects sooner. You send part of the team to Bermuda (i.e., remove them from the project), and the project finishes sooner.
It was conceived as a response to Brooks’s law (an observation about software project management according to which “adding people to a late software project makes it later”). So, if you remove people, should it go faster?
In my experience, each new person joining the team takes away about 1/3 of the time of one person already producing during the new person’s onboarding and until they ramp up to be fully productive.
So removing someone who recently joined may increase productivity.
Other reasons why it could work are if there are too many conflicts in the team. Removing people who are not aligned with the team goals may help.
If there are way too many people in a team, the communication overhead may be significant enough to hinder productivity. In this case, splitting the team may work well (which is technically not the same as removing people from the project).
Otherwise, removing people only reduces the capacity to build more in less time.
Anyway, I was just sharing the Bermuda Plan because it’s always fun to talk about it. :-D
If you like this post, please share it (you can use the buttons in the end of this post). It will help me a lot and keep me motivated to write more. Also, subscribe to get notified of new posts when they come out.