Defect avoidance
Not introducing them is much better than looking for and fixing them later.
I’ve realized that I wrote quite a bit about avoiding defects in the past in posts that are not focused on this topic. I think this is a topic that deserves a post of its own. Much of the QA effort goes into detecting and removing defects, but QA management should go beyond that, into a proactive approach to avoiding the defects from even coming to be. If you reduce the introduction of defects by any percentage, given the same effectiveness in detection and removal, you should see a similar decrease in escaped defects. So, why not? :-)
The first thing we need to understand is WHERE defects are introduced.
Defect propagation
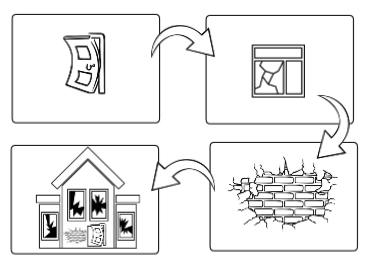
A defective behavior in the software is called a failure. One or more faults may cause this behavior in the code. While this fault may have been introduced directly into the code, it may have as well been transposed from another artifact.
By gathering the information on the actual root cause, the origin of the defect, we can detect which steps of our process are more prone to insert faults (or which are the cheapest defects we can avoid). We can then decide to take different actions to minimize the rate of introducing defects. Some approaches can be:
The software development process is knowledge transformation and enrichment. We define a problem and enrich that knowledge with the requirements for a solution. Then we analyze the requirements to transform them into technical specifications that support building such a solution. Next, we develop code that describes this solution to a machine. We then go back to the requirements and technical specifications to design tests that we will execute to verify this code.
Each transformation is done by humans or based on an artifact built by humans. In any case, humans will make mistakes, faults. These faults are wrong information that will go through the transformation process with the correct information to generate the next artifact. It means the faults will propagate from one artifact to another, accumulating in the final artifacts.
There are many strategies to reduce this cumulative effect by identifying these faults as early as possible (shift left), reducing propagation. This is not the focus of this post. The focus of this post is to avoid them being inserted at all.
We understand that defects may be found at any stage of development, but it doesn’t mean that it’s there where they were first introduced. They might have been introduced earlier and propagated to where we found them. This means that we need to investigate to identify where they were actually inserted.
Root Cause Investigation
While the root cause investigation might have detected the fault in the code that is causing the defective behavior, it is NOT the root cause.
Root cause investigation is the process of finding the cause of an incident or a group of similar incidents. There are different approaches for the root cause investigation.
For high-traffic software, often, one-time incidents are just treated at the incident level, and no root cause investigation is performed until the incident happens above a specific frequency. Sometimes, users make mistakes or have unique situations, and it might not be worth making permanent changes to the software just for one case or another.
When conducting a root cause investigation, teams often stop at the cause at the code level and fix it there. That fault may be the one causing the software failure, but it might not be the root cause.
In a software development process, defects propagate. Artifacts built at the beginning of the process (requirements, mockups, etc.) will have faults. These faults will carry over to intermediate artifacts (technical specifications, models, etc.). When the last* artifacts (code, tests, manuals, installation guides, etc.) are developed, these faults will be built into them. This is expected. We even have a name for the quality assurance process that ensures we have done all these transformations consistently, which is verification.
*by “last,” I mean artifacts delivered without necessarily being used as input to build other artifacts in the same process.
I had a professor at the university who used to say: “-If you lied in the requirements (or whatever your source of truth is), verification is about making sure you told the same lie in all subsequent artifacts, and it will be there in production.”
While the root cause investigation might have detected the fault in the code that is causing the defective behavior, it is NOT the root cause. Finding the actual root cause (the origin of the defect) will enable you to start focusing on delivering better in future releases by preventing defects from even happening.
So, you found the root cause, which is where and why the defect was originated. What do you do next?
Analyze the data
By gathering the information on which activity introduced the defect, we can detect which steps of our process are more prone to insert faults (or which are the cheapest defects we can avoid).

Now, you start collecting the information. You will want to collect:
- Artifact type where the defect was inserted
This will tell you which types of artifacts are more defect prone. May want to start with the types that are contributing the most.
- Date
Once you make a change to avoid inserting defects, you will want to compare before and after the change.
- Artifacts affected
One attribute related to the effort to fix the defect is how much the defect spread to other artifacts. There may be critical artifacts, like artifacts that go to clients and partners, that you may want to prioritize getting right. This will allow you to know what contributes to defects in the one you are looking to improve.
- Effort to fix the defect (in all affected artifacts)
Knowing what is causing you higher costs is also an excellent criterion to decide where you want to focus first.
- The business impact of the defect (t-shirt sizing is fine)
Sometimes, what is causing you higher internal costs (the effort to fix) is not what is causing higher costs to the business.
- Category (you can create any categories you would like, this is just to help you group similar defects)
Having categories may guide you on how to improve. If requirement specifications often miss information, you may want to invest in requirement elicitation training or create specific sections in your requirement template. That would be different from contradicting information, where you may want to invest more time selecting your requirement providers and have them cross-check what they tell you.
- A description of what the defect was
This is to give you context and allow you to see the defect and verify the data you collected. You may want to re-categorize it, for instance.
- Artifact where the defect was inserted
Again, this is for context. It helps you if you want to go and see where the defect was inserted.
Finally, avoid the defects!

The most crucial piece of this post might be this one. This is how we actually improve our process to reduce the number of defects. All the things we discussed so far are tied to improving the management of the incident, not having fewer incidents to manage.
So, what can we do?
- Improve the templates. It will help you capture missed information and minimize ambiguity for both who writes and who reads the artifact. If you see that something is confusing, you may want to break the multiple aspects of it into different sections of a template. If information is often missed, you may want to include a specific section for it. You may also opt for a different template altogether.
- Invest in training. Often, people don’t understand how what they are building will be used in future activities, or sometimes they don’t know how to best use the tools and templates adopted by the organization. Or they may simply need the training to perform their roles better. You will want to focus your training on how they should do the activities AND how others rely on what they did to perform their tasks. This will increase their collaboration and give them a better understanding of how things need to be structured.
- Improve the practices. If you see that you miss some test cases in your tests, you may want to run your tests against code mutations before you conclude your testing activity. If you are doing ad hoc code reviews, you may want to adopt checklists, especially if many of your reviewers are new to the codebase or are not experts in some relevant aspects. If you often get conflicting information finding its way into your requirements, maybe you want to improve your selection of requirement providers and their collaboration channels.
- Eliminate the activity. If there’s no activity, there are no mistakes! ;-) I’m not joking. Sometimes you can adjust other activities to make up for the information loss. Other times you can replace the activity for another one earlier or later in the process.
If you like this post, please share it (you can use the buttons in the end of this post). It will help me a lot and keep me motivated to write more. Also, subscribe to get notified of new posts when they come out.
Benefits

By identifying these improvement opportunities, you can reduce the number of defects being added. There will be fewer defects to be captured and fewer defects escaping to production. The cumulative result will lead to fewer reported incidents.
Fewer reported incidents mean less effort in fixing defects, less high-severity stressful incidents, fewer interruptions to the planned work, higher productivity, satisfaction (on all sides), and a better image for the business and the product.
The same approach should also be followed once a defect is detected during any QA activity, whether a test, a review, or an inspection. It allows for fixing the entire software consistently (not just the code).
While doing that only for defects found in production will keep you focused on the type of faults that escape QA, doing it for all of them will ensure you save time and effort throughout the process and increase productivity.
This information will also help you with your QA shift-left approaches. Once you know which activities are more defect-prone, you can introduce QA activities to reduce the number of defects that propagate further. Here are some QA activities you may consider for certain artifacts:
- For code, you can adopt code reviews, code inspections, and tests.
- For tests, you might want to adopt code mutations.
- For models, you might choose to adopt checklists.
- For textual documents, checklists, reviews, inspections, perspective-based reading techniques, and other practices may be employed.
- For almost any artifact, walkthroughs will be an option.
Many practices can be employed to improve the quality of these artifacts. The best one will depend on each scenario.
If you have other ideas for avoiding defects, information you would like to collect, or other comments, please share in the comments below! :-)